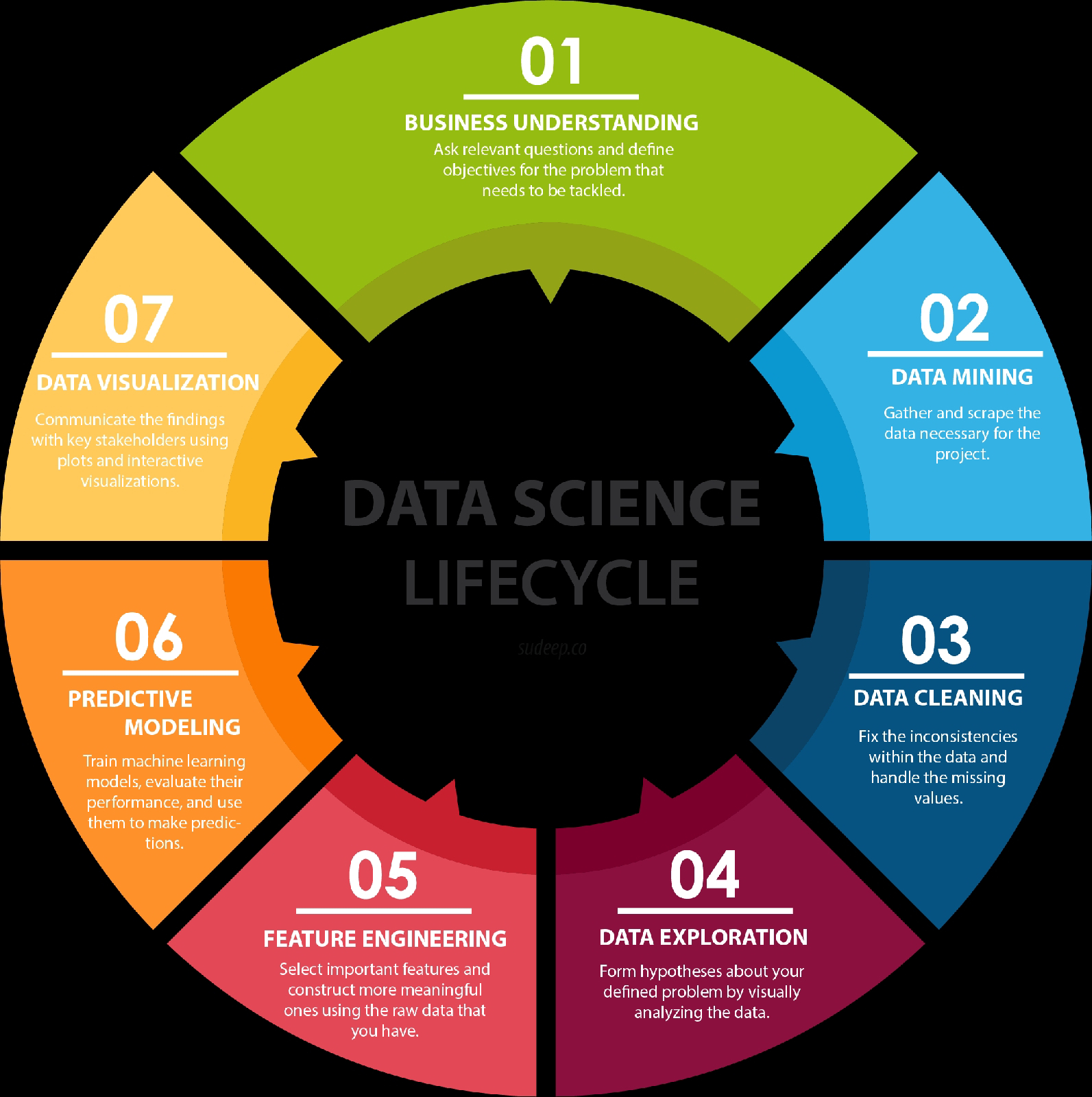
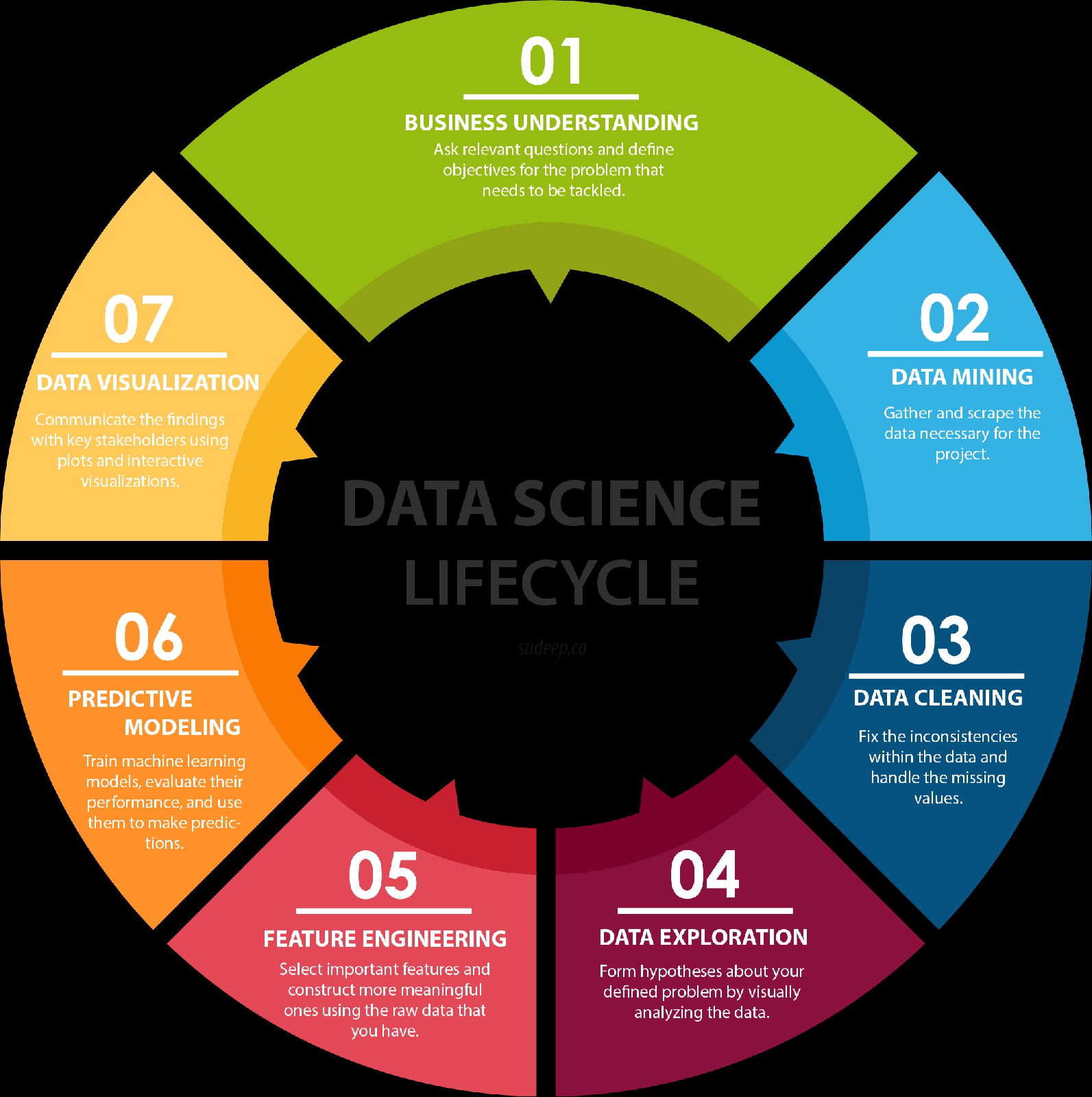
“चुप रहना” एक ऐसी शक्ति है जो हमें किसी भी बात को गहराई से समझने की और काम करने की ऊर्जा देती है l चुप रहने से हमारा mind ज्यादा काम करने लगता है और हम ठीक समय पर सही निर्णय लेने में सक्षम होते हैं l यह हमारी आत्मिक शक्ति का मुख्य स्त्रोत है, जो आज कल के समय में हमारे लिए बहुत ही मुश्किल है l यह हमारे मन को शांत करता है l शांत रहने से हम अंदर से यानि दिल से सच्ची खुशी का महसूस करते हैं, जिसका अंदाज़ा हम खुद भी नहीं लगा सकते l इससे हमारी संकल्प शक्ति भी बढ़ती है l इसलिए जो लोग कम बोलते हैं, उनके द्वारा कही गई बातें जल्दी सच हो जाती हैं क्योंकि वे लोग सकारात्मक विचारों के होते हैं और उनका मन अंदर से बहुत शांत होता है l जब किसी परेशानी का हल असंभव सा दिखाई देता है तो कुछ देर चुप रहकर अकेले में बैठ कर उसे बड़ी आसानी से हल किया जा सकता है l चुप रहकर ही भगवान या परमात्मा से भी सीधी बात की जा सकती है l जीवन में खुश रहने के लिए चुप यानि शान्ति का विशेष महत्व होता है l
दोस्तों! आज हम मौन यानी silence के बारे में बात करते हैं! देखिये हम इतना ज्यादा बोलने के आदि हो चुके हैं habitual हो चुके हैं कि मानो हम मौन रहना भूल ही चुके हैं! बोलना हमें संसार से जोड़ता है,बोलना हमें society से जोड़ता है, हम औरों से जुड़ते हैं लेकिन चुप रहने से हम अपने आप से जुड़ते हैं! हम इस आपाधापी में इतना खो चुके हैं कि हम खुद को भूल चुके हैं और खुद को भूल जाने की वजह से ही बहुत सारी mental और physical बीमारियों ने हमें घेर लिया है!जो हम depression की बात सुनते हैं, anxiety की बात सुनते हैं, insomnia की बात सुनते हैं, इनका root cause जो है वो केवल यह है किहम इतना ज्यादा विचारों में खो चुके हैं, इतनी ज्यादा tension को हमने अपने सिर पर ले लिया है कि control से अब situation बाहर चले गयी है, तो अपने आप सेenjoy करना सीखना है!
मेरा एक friend उस दिन बात कर रहा था कि “मैं चाहता हूँ कि people should enjoy my company, तो उनसे सवाल किया गया कि “Do u enjoy your own company? क्या आप खुद अपनी company enjoy करते हैं? क्या आप आधा घंटा या एक घंटा केवल अपने साथ बैठ सकते हैं? Just alone, without any book, without any movie, without any music, without any smartphone? Can you stay with yourself just alone?
दोस्तों! अगर आप ऐसा कर सकते हैं तो आप स्वास्थ्य को हासिल कर सकते हैं! स्वास्थ्य शब्द का मतलब जो हमारी हिंदी में होता है “स्व में स्थित होना, अपने आप में स्थित होना, अपनी ही company enjoy करना! तो दोस्तों स्वस्थ होने के लिए कुछ पल अपने आप के साथ बिताना शुरू करें, बहुत ज्यादा नही केवल आधा घंटा अपने आप को देना शुरू करें! कुछ समय silence में बैठ जाएँ, silence में ! अपने विचारों के,जो अपने मन के अंदर विचार चल रहे हैं उनके एक दृष्टा बनकर, साक्षी बनकर, witness बनकर, यानी अपने अंदर जो विचार चल रहे हैं, उनसे हम छुटकारा पा सकें कुछ समय के लिए और अपने आप के साथ enjoy कर सकें,केवल अपने आप के साथ- चुप बैठना, मौन हो जाना! हम बाहरी रूप से तो कई बार बोलना बंद कर भी देते हैं लेकिन अंदर हमारे तब भी बोलना ज़ारी रहता है, तो बाहरी रूप से बोलना थोड़ा बंद करना है और खुद के अंदर से भी बोलना बंद करना है!
तो बाहर से तो मौन कर लिया, हमने जुबान बंद कर ली, आँखें बंद कर ली, अपने आप को ही बैठे देख रहे हैं अंदर! हमारे mind की जो screen है इस पर जो हमारे विचार हैं reflect होते हैं! एक विचार जाता है, कुछ देर के लिए फोटो सामने रहती है, कुछ शब्द सामने आते हैं, हमने किसी को कुछ कहा और थोड़ी देर बाद वो गायब हो जाते हैं! आप एक silent witness बनकर उन्हें देखते रहें just जैसे आपका इनसे कोई वास्ता नही है, कोई लेना देना नही है, थोड़े ही समय बाद आप देखेंगे कि विचार गायब होने शुरू हो गए हैं और इसी प्रकार एक silent witness बनकर आप कुछ देर देखते रहें तो एक ऐसी अवस्था आती है जिसे कहते हैं “thoughtlessness” यानी बिल्कुल विचारशून्य अवस्था और यह अवस्था इतनी enjoying होती है, इतना इसमें आनंद आता है that the blessings flow in towards you automatically, the entire universe as if pouring inside you. You start enjoying that state, that state is the state of bliss, आनंद की अवस्था प्राप्त होनी शुरू हो जाती है!
थोड़ा समय लगता है इस चीज़ की practice करने में, रोज आधा घंटा, 20 मिनट, 15 मिनट हम शुरुयात करके देखें! दोस्तों! एक बार आप अपनी company enjoy करना शुरू कर देंगे, यकीन मानें लोग भी आपकी company enjoy करना शुरू कर देंगे, केवल बैठने मात्र से आप कुछ नही भी बोलेंगे, तब भी लोगों को आनंद आएगा, खुशी मिलेगी केवल आपके पास बैठने से! यकीन मानिए दोस्तों उपवास शब्द हम कहते हैं न उपवास रखा है आज मैनें व्रत रखा है, उप का मतलब नजदीक और वास का मतलब बैठना, अपने ही नजदीक बैठना, अपने ही आप के पास बैठना और अपने आप से जरुरी इस संसार में तो और कुछ नही है न? आप खुद अपने ही आपको जब enjoy करना शुरू करेंगे तो लोग भी आपके पास बैठना enjoy कर सकेंगे! तो दोस्तों बहुत सारी mental और physical diseases से छुटकारा मिल जाएगा अगर हम अपने आप के पास बैठना शुरू कर दें! देखिये nature भी हमें यही सीखाती है- “silence”! सूरज चमक रहा है, चाँद सितारे चमक रहे हैं, धरती अपने स्थान पर टिकी हुयी है, यह nature ही तो पल पल silent है, सब कुछ करती है लेकिन witness रहती है, just witness! कभी सूरज यह कहकर जतलाता नही कि देखो मैनें तुम्हे heat दी, मैनें तुम्हे energy दी, मैनें तुम्हे रौशनी दी, मेरी वजह से तुम्हारा जीवन है, मैं ना हूं तो तुम मर जायो, यह सूरज कभी नही कहता, the sun never says like this! हम लोग बोलते रहते हैं, देखो मैनें तुम्हारे लिए ऐसा किया, मैनें तुम्हारे लिए वैसा किया, इस तरह से हम जतलाते रहते हैं पर कुदरत कभी नही जतलाती, it just stays silent, nature से हम यही चीज़ adapt करते हैं, हम भी इसी silence में जाने की कोशिश करते हैं!
देखो रात को हम नींद में क्या करते हैं? नींद भी एक ऐसी अवस्था है जहाँ पर हम सब कुछ छोड़ देते हैं और silence में उतर जाते हैं! अगर रात को भी आपके दिमाग में बहुत सारे विचार चल रहे हों, कोई tension दिमाग में हो तो आप देखते हैं कि नींद आनी मुश्किल हो जाती है, नींद नही आती! insomnia जैसी जो अवस्था आती है, अनिद्रा की बीमारी जिसे कहते हैं , रात को नींद न आना, उसका root cause यही है कि इतने ज्यादा विचार चल रहे हैं कि वो नींद के आने में बाधा दाल रहे हैं! ध्यान और नींद में बहुत थोड़ा सा फर्क है! नींद जो है,उसमे अपनीconsciousness को, अपने आपको हम भूल जाते हैं पूरी तरह से और तब कुदरत की ऊर्जा हमारे अंदर उतरनी शुरू होती है लेकिन ध्यान में हम consciously अपने विचारों के दृष्टा बन जाते हैं, अपने विचारों को शांत करके बैठ जाते हैं और उसके बाद कुदरत की ताकत हमारे अंदर आना शुरू कर देती है!
आप देखिये रात की हमारे 6-8 घंटे की जो नींद है, उसके कारण हमारे दिन के जो 15-16-17 घंटे हम कितना energetic feel करते हैं और बाकी के समय में हम अपनी सांसारिक कार्येवाही कर सकते हैं!इसीप्रकार अगर हम थोड़ा समय अपने आप के साथ enjoy करना मतलब अपने ध्यान में enjoy करना शुरू कर दें जो कि consciously हम बैठें और consciously हम अपने विचारों को शांत कर पाएं तो यह एक ऐसी powerful state होगी जिसको normally आप नींद में आप enjoy करते हो, नींद में आपको जितनी energy मिलती है, इस ध्यान से आपको कई गुना ज्यादा energy प्राप्त होगी और उसके बाद एक बार energy आपको वो मिली then you enjoy talking to everybody, you can distribute this power, this energy! आपके संकल्प में एक शक्ति आणि शुरू हो जाती है, एक power आनी शुरू हो जाती है, the power of silence, मौन की ताकत, छुपी की ताकत, यह छुपी आपको बहुत ताकत देती है, बहुत ज्यादा!
तो दोस्तों इसके लिए थोड़ी देर चुप रहने की practice करनी है! कभी कभी दिन को भी इस practice को बना के देखिये, जब आपके पास time हो, सफर कर रहे हैं, जरूरी तो नही हर time सोचते ही रहें, कुछ time thoughtless state को पाने की कोशिश करें यानी केवल अपने विचारों के साक्षी बन जाएँ, दृष्टा बन जाएँ as if you are not at all related to them, उन विचारों से आपका कोई लेना देना नही है, विचार आ रहे हैं, जा रहे हैं, दूसरा आता है, तीसरा आता है, इस तरह आना जाना लगा रहता है, लेकिन आप केवल उनके दृष्टा बनते हो, देखते रहते हो, उनसे आपका कोई वास्ता नही है!कभी कभी मन किसी विचार को पकड़ने की कोशिश करता है तो आप हलके से उसे झटक देते हो कि I don’t need, I just need to observe, मेरा उससे कोई लेना देना नही है और you come back to yourself! अपने ही स्वांस के आने जाने को हम observe करते हैं, इस अवस्था को विपश्ना meditation कहते हैं , बहुत से लोग इसे साक्षी यानी witness meditation भी कहते हैं, बहुत सारे forms हैं लेकिन main crux को हमें पकड़ना है, conclusion को पकड़ना है वो है विचारशून्य अवस्था को पाना , वो आप जैसे भी करके पा सकें that will provide a great amount of energy!
दोस्तों! इसके द्वारा जो संकल्प शक्ति प्राप्त होती है, जो अंदर से ऊर्जा प्राप्त होती है, उसके द्वारा हम संसार के महान से महान कार्य कर सकते हैं तो let's enjoy the power of silence - so be silent & enjoy life!